

The Illusion of the "Illusion of Thinking": Debunking Apple's Study & Understanding the True Nature of LLMs
The State of Industrial AI - E93

You've likely encountered recent sensational headlines claiming AI models, like ChatGPT and Gemini, "don't actually reason—they just memorize." One particularly viral tweet with 13.7 million views sparked heated discussions across social media and mainstream outlets, including the Guardian, which quoted an Apple research paper as "pretty devastating." But what is the truth behind this provocative claim? Let's dive deeper.

Are LLMs Really Just Memorizing Patterns?
The Apple paper, provocatively titled "The Illusion of Thinking", argues that LLMs fail in complex reasoning tasks, essentially alleging these models merely recognize patterns without true computational reasoning. They demonstrated this by testing models on puzzles like the Tower of Hanoi, checkers games, and the classic "fox and chicken" river crossing scenario. Unsurprisingly, the results showed that models' performance deteriorates with increasing complexity.

However, the fundamental misunderstanding in Apple's paper, and what mainstream media largely missed, is that nobody ever claimed these models were algorithmic calculators. Indeed, we have known for years that LLMs struggle with exact computation without assistance. These are probabilistic systems designed to predict plausible outputs, not deterministic machines executing precise algorithms.
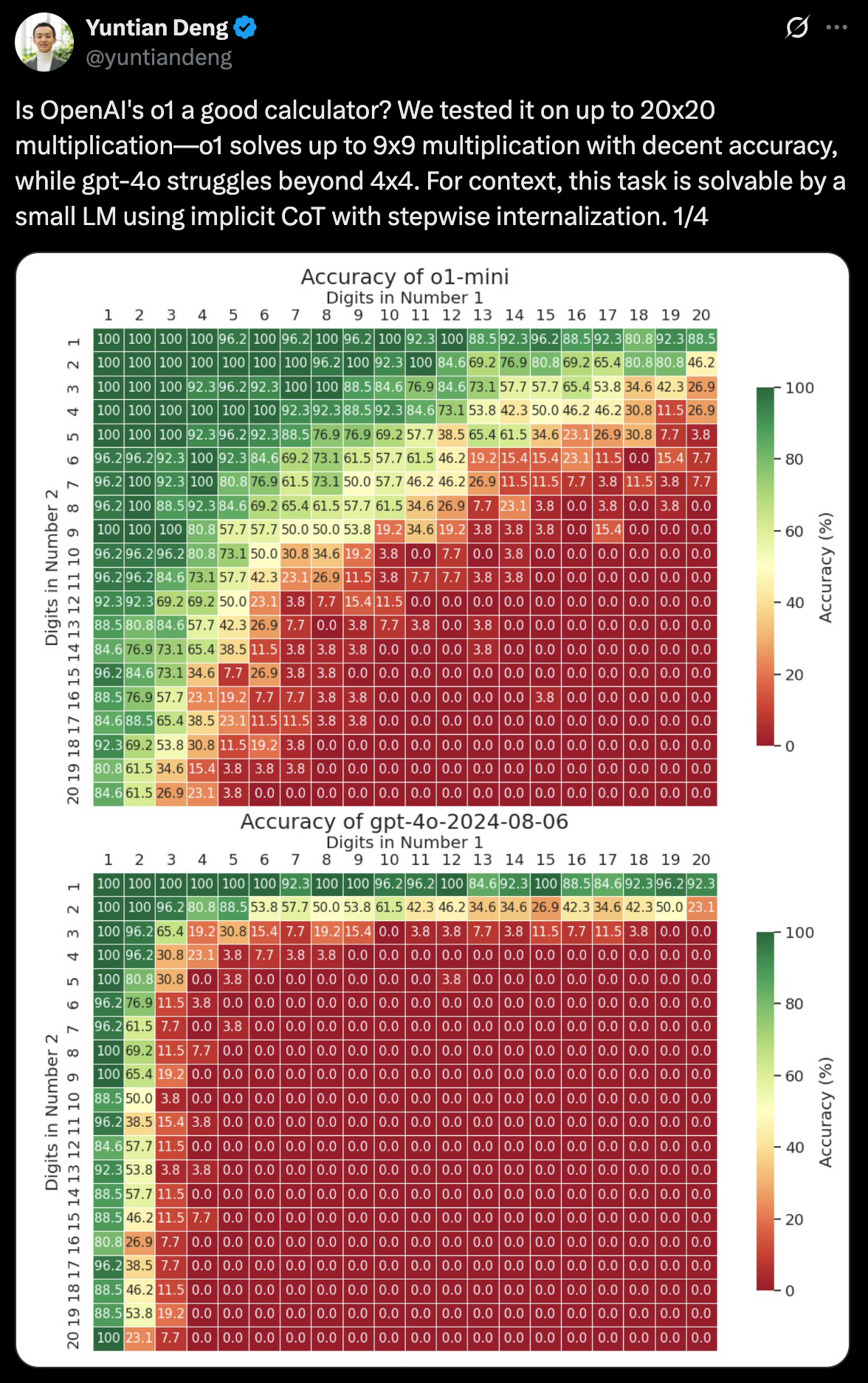
Digging Deeper into the Apple Study
Further analysis by researchers quickly surfaced several critical flaws in Apple's methodology. The excellent response paper "The Illusion of the Illusion of Thinking" (ironically co-authored by Claude 4 Opus, an AI model) pointed out that some of the test questions were logically unsolvable. Moreover, the models were restricted by token limits; some reasoning chains required more tokens than the model could possibly output, forcing incomplete or truncated answers.

The broader expert community wasn't shocked by Apple's findings either. Renowned researcher Professor Rao highlighted on Twitter that these

"fundamental barriers to reasoning" have been openly discussed since at least December 2023. Furthermore, Gary Marcus’s Guardian op-ed pushing this "AI illusion" narrative simply echoed already established academic discussions.

Holding Two Thoughts at Once: The Reality Check
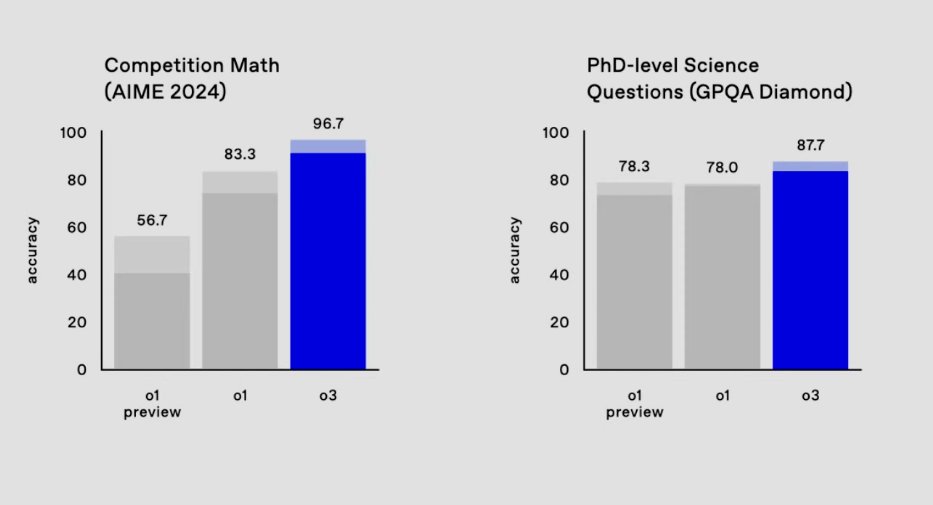
The critical takeaway is nuanced: yes, current LLMs, like Gemini, Claude, and OpenAI’s newest 03 Pro, do hallucinate plausible but incorrect responses, especially when they can't use external computational tools. However, dismissing their reasoning capacity outright overlooks their rapid, documented improvements in reasoning tasks when allowed to leverage tools or computational assistance.
{kind=link}
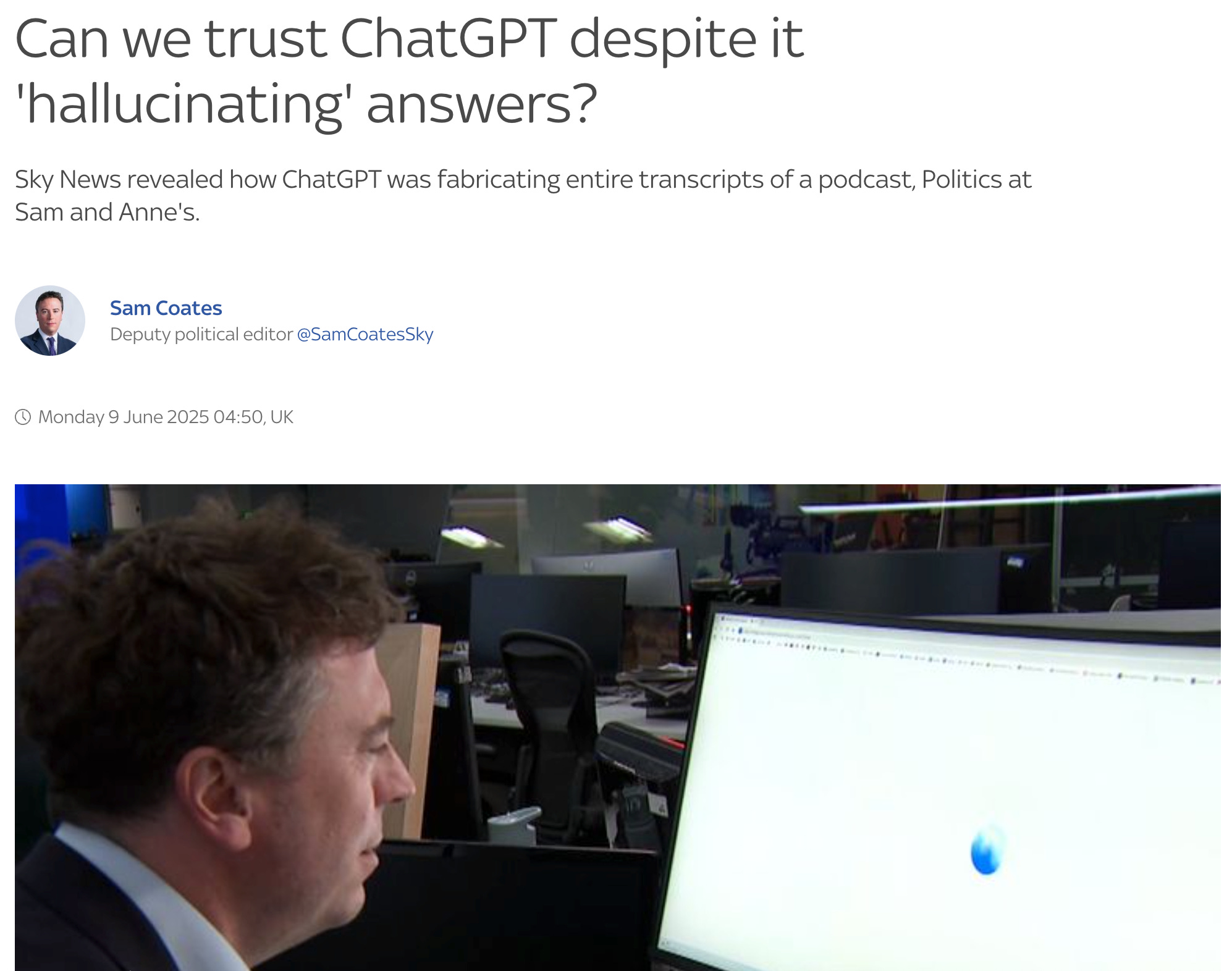
This exact phenomenon is highlighted in a recent Sky News segment, illustrating the surprising and plausible errors these models produce without validation mechanisms.
Benchmarks, Reality, and Recommendation
We must also remember benchmarks are not everything. As evidenced by the latest Axios coverage, AI-driven economic shifts are real, even if models aren't "perfect calculators."
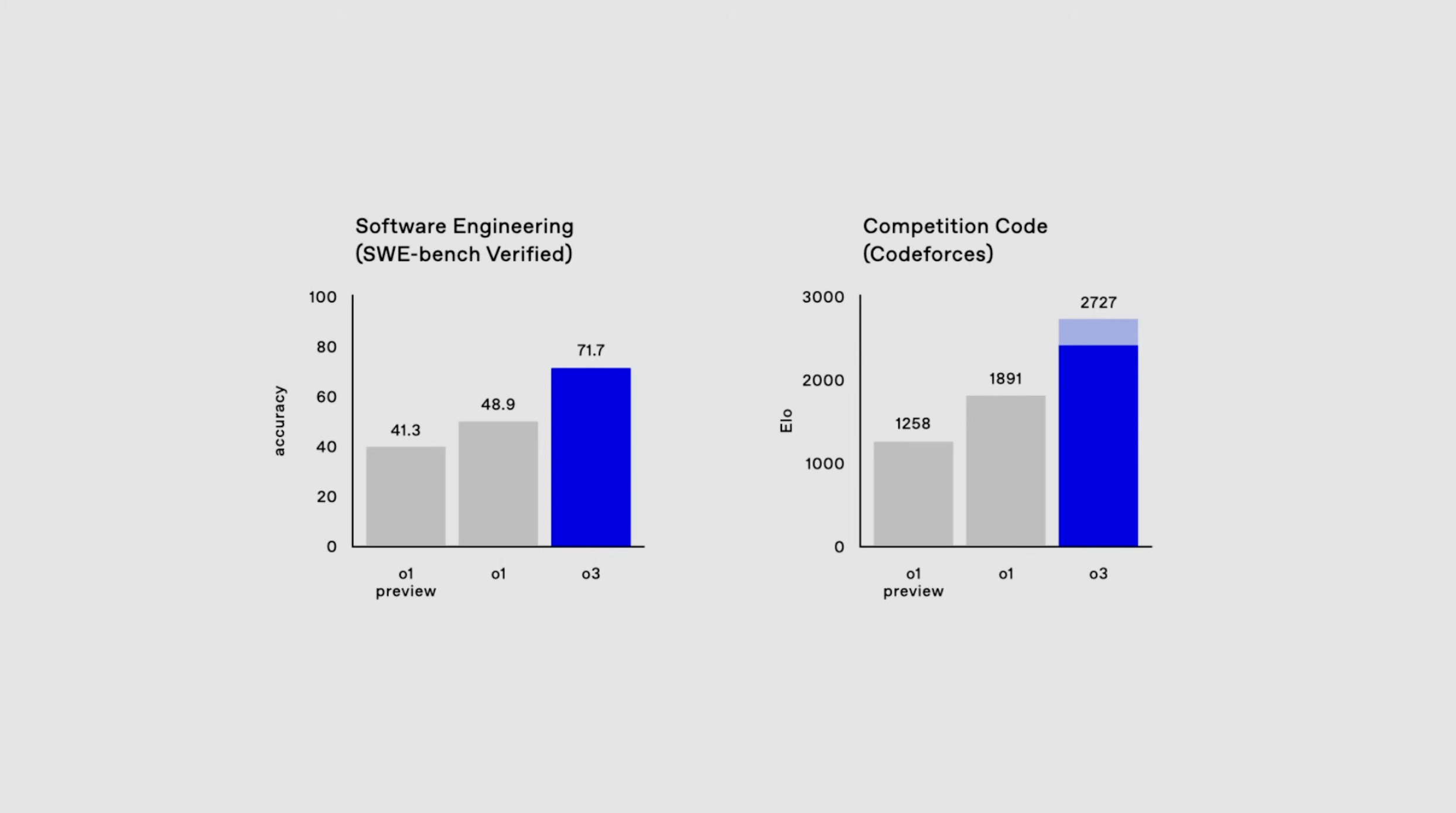
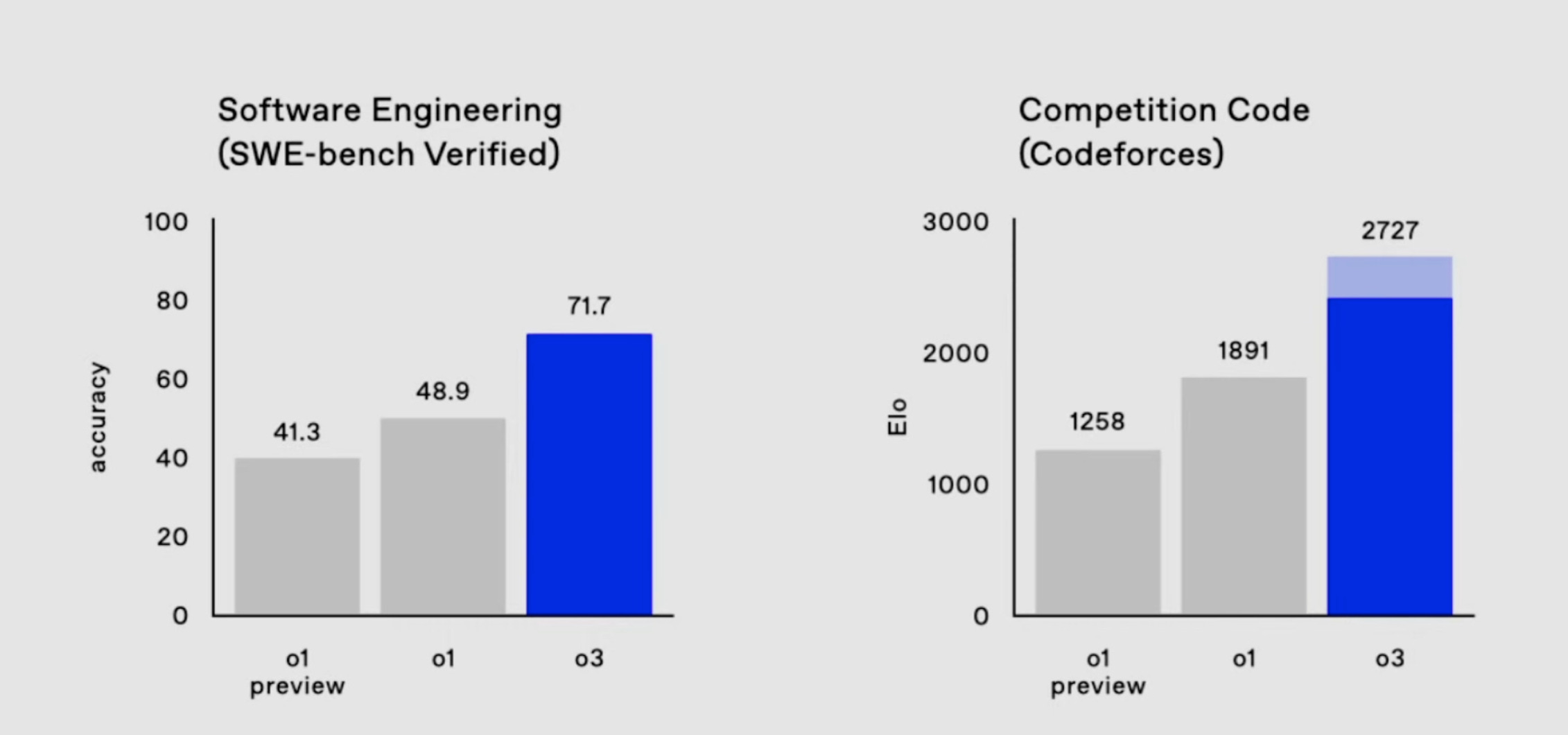
OpenAI’s highly-anticipated 03 Pro, despite impressive headline metrics, has shown inconsistencies compared to its early December preview.
{kind=link}
If you're seeking reliable, accessible AI for personal or professional use, Google's Gemini 2.5 Pro currently offers the best freely available performance—particularly impressive on reasoning benchmarks and multimedia generation tasks, as showcased in the humorous yet technically impressive "Kalshi" ad.
Conclusion & the Big Picture
In conclusion, the idea that LLMs are mere pattern-memorizers without any reasoning capacity is profoundly misleading. Yes, they hallucinate. Yes, they falter in exact computation without tools. Yet, they increasingly excel in reasoning tasks when properly equipped.
To gain a deeper insight into how such AI systems are being productively deployed in industry and science, see our previous deep dive into Google's groundbreaking "AlphaEvolve" agent.
Enjoyed this?
Love deep industrial AI stories? Subscribe free for weekly analysis; paid tier unlocks notebooks & live Q&A