Google DeepMind just shipped an agent that rewrites its own codebase—then distills the wins into the next Gemini model. The ripple effects for chips, power-grids and climate tech are bigger than most realize.
TL;DR:
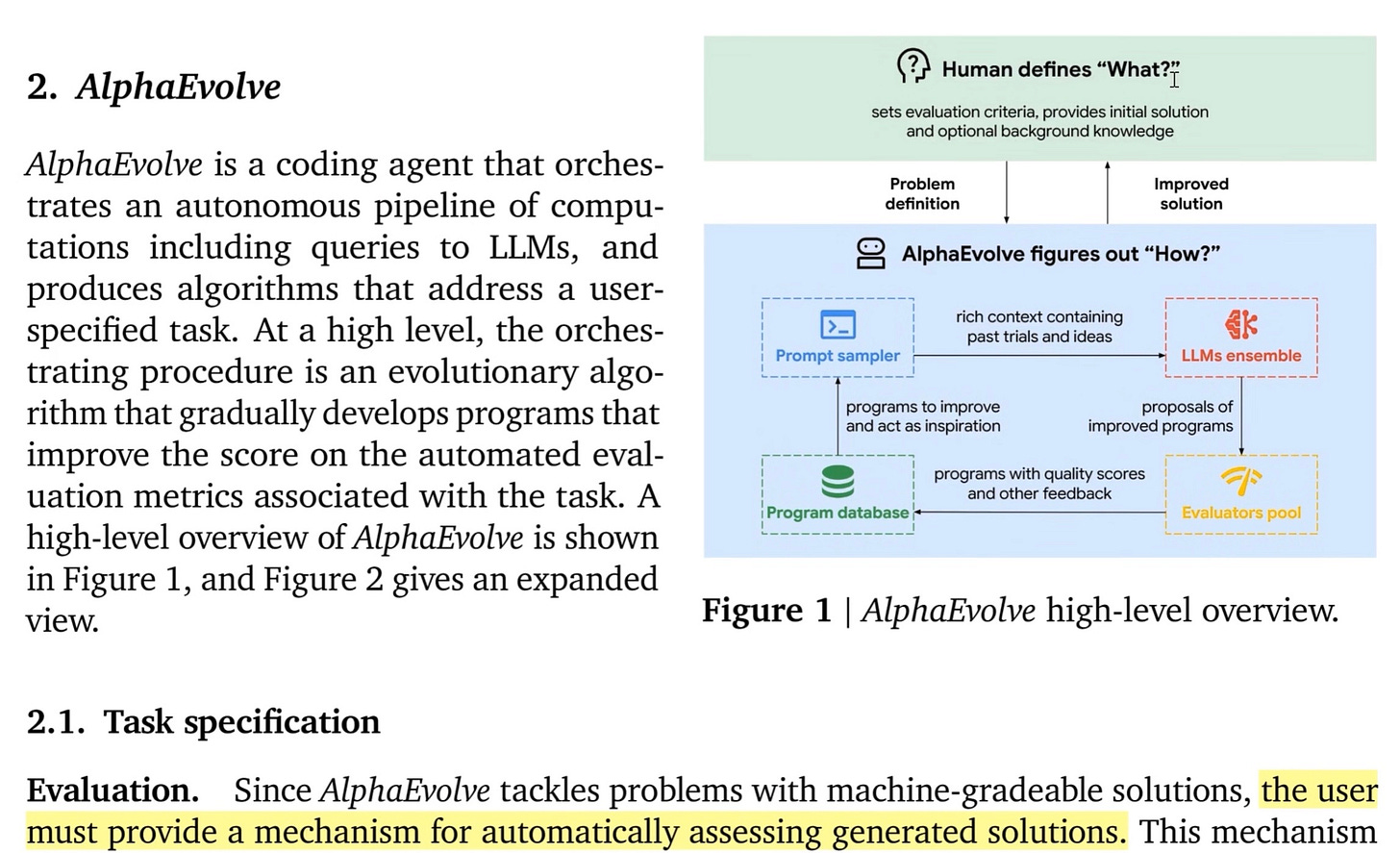
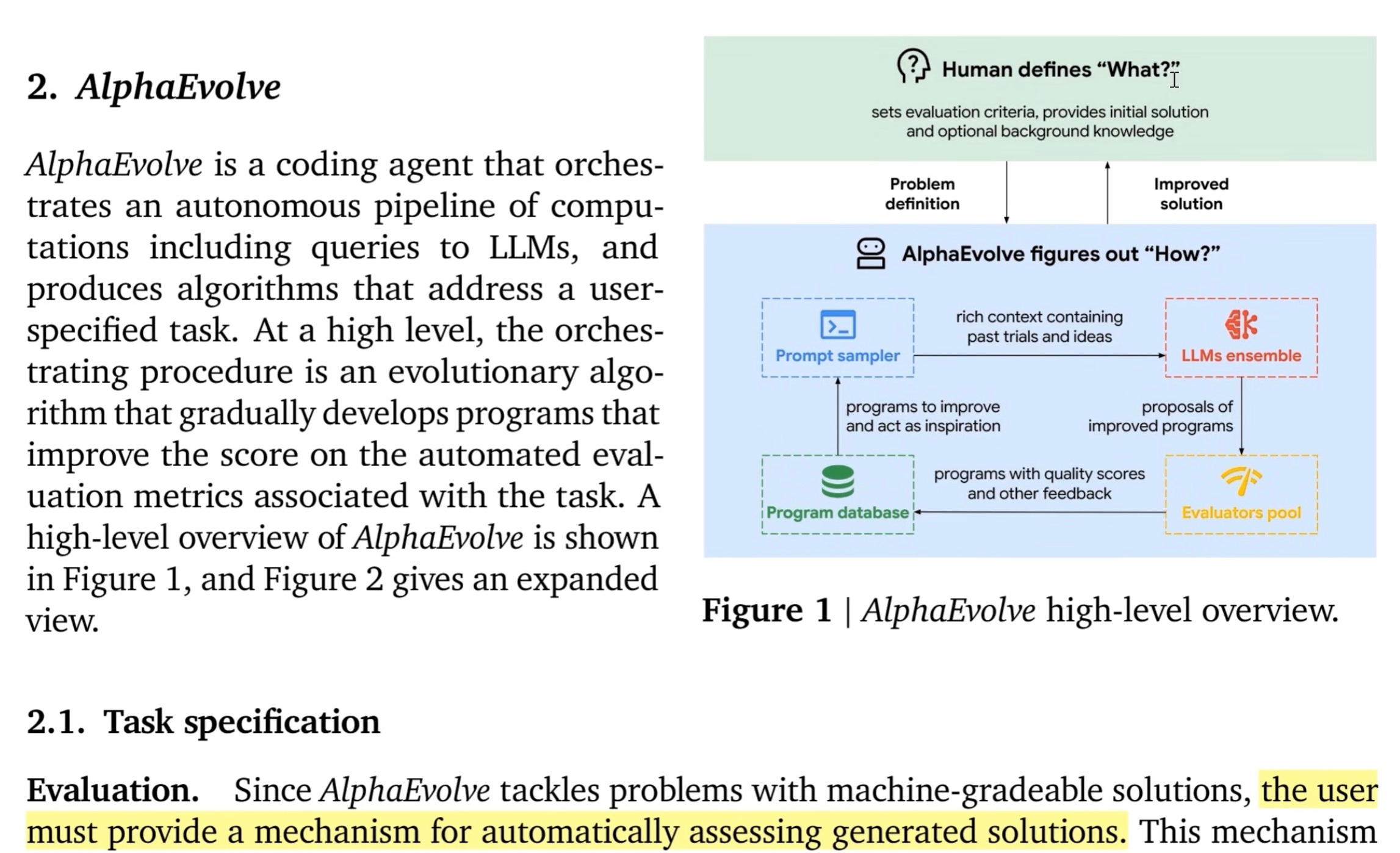
AlphaEvolve (blog, Paper) loops prompt → mutate → score → save until it finds better code.
Already reclaimed 0.7 % of Google’s production compute and cut Gemini training time by 1 %.
Broke a 56-year math record with a rank-48 tensor decomposition (Nature precedent).
Biggest bottleneck: you still need machine-checkable metrics. Biology & climate sims are next.
Athlete’s dilemma: labs that keep strict safety guard-rails risk losing users; FT says OpenAI has already shortened O-series safety evals.
1. From Co-pilot to Co-author
Most devs know Codex. Nice autocomplete, but humans still steer. AlphaEvolve flips it:
You upload code + metrics.
Prompt-sampler recalls successful prompts / diffs (see yellow box below).
Gemini Flash fans out ideas; Gemini 2 Pro keeps the diffs that score higher.
Evaluator pool runs your metric (accuracy, latency, kWh, CO₂).
Climate models — evolve solver kernels; 1 % training cut = megatons less CO₂.
5. Four Levers That Will Super-Charge AlphaEvolve
Bigger contexts (10 M tokens in Gemini 3) —> lets the agent load the whole evolutionary DB in-prompt
Better base LLM leads to better agent —> “performs increasingly better as the underlying LLM improves”
Distillation loop fuels next Gemini —> highlight “distilling AlphaEvolve-augmented performance…”
Evolve the search algorithm itself —> paper note “evolving a search algorithm to find it”
6. Safety, Regulation & The Athlete’s Dilemma
Bottleneck reality — even Google admits many domains still need wet-lab or hardware assays;
FT safety-window scoop — Financial Timesexclusive reports OpenAI halved its O-series safety-eval period under commercial heat.
Athlete’s Dilemma (aka “dope or lose”):
Labs assume rivals will loosen guard-rails → incentive to ship faster, safer-ish models get sidelined.
Regulatory vacuum means whoever answers the most questions wins user-share.
Jason Wei’s warning:
“AlphaEvolve is deeply disturbing for RL diehards… What an alpha move to keep it secret for a year.” — @_jasonwei
Metric-as-Moat strategy — own the evaluator: if your grid-CO₂ simulator is proprietary, only your in-house AlphaEvolve can optimize against it.
Policy knobs — throttle iteration cadence on infrastructure, mandate diff-chain provenance (the still-human-readable prompt)
In short: without guard-rails, recursive agents race like untested performance enhancers. Until regulation levels the field, expect ever-shorter safety check-lists and faster self-improvement loops.
Bonus Clip — How a 15-Second Diff Mosaic Beat a 50-Year Record
Before you hit play: each colored panel you’ll see is a candidate algorithm that AlphaEvolve generated for multiplying 4 × 4 complex matrices.
Grey squares = scalar multiplications.
Lines connect how partial products combine.
The agent explored tens of thousands of these mosaics in a single overnight run, scoring each against a tensor-rank metric. Iteration 12 surfaced the rank-48 solution you just read about—one fewer multiplication than the Strassen-based record from 1969. Saving a single scalar op at this small size sounds trivial, but when you recursively apply the pattern to 4096 × 4096 matrices (the kind that dominate GPU workloads) it snowballs into double-digit percent speed-ups and measurable energy savings in data-centre scale AI training.
Quick Poll — Your Call on the Athlete’s Dilemma
Loading...
Enjoyed this?
Love deep industrial AI stories? Subscribe free for weekly analysis; paid tier unlocks notebooks & live Q&A