



Video Generators: Sora vs. Veo2 and Their Promise for High-Quality AI Training Material
The State of Industrial AI - E84

Recent progress in text-to-video generation has accelerated with platforms like Veo 2 (VO2). Access to VO2 remains tightly controlled, as noted by remarks suggesting Demis Hassabis’s personal distribution process. Comparisons drawn between VO2 and other models (e.g., Sora) reveal that VO2 reliably executes specific prompts with strong fidelity—albeit with a stylized, Pixar-like appearance. This contrasts with Sora, which might achieve higher resolution but struggles with consistent adherence to text instructions.
Implications for 2025
Observers anticipate that a new wave of technology, often referenced as “O3 for multi-modality,” could arrive within the next year or so. The excitement stems from the notion that breakthroughs in text generation (GPT-4 and beyond) will quickly translate into visual and auditory domains. The underlying principle is that success in one modality (e.g., advanced language models) indicates similar methodologies could extend to text-to-video.
Core Technical Insight: “Chain of Frames” Approach
Lukasz Kaiser’s Concept
Lukasz Kaiser’s discussion offers a foundational view of generating sequences of frames—parallel to the notion of a “chain of thought” in language models. Models benefit from simulating future states or frames before producing a final answer or image sequence. This capacity for short-term prediction can improve realism and controllability, paving the way for text-to-video systems that capture real-world dynamics more effectively.
OpenAI O-Series Methods
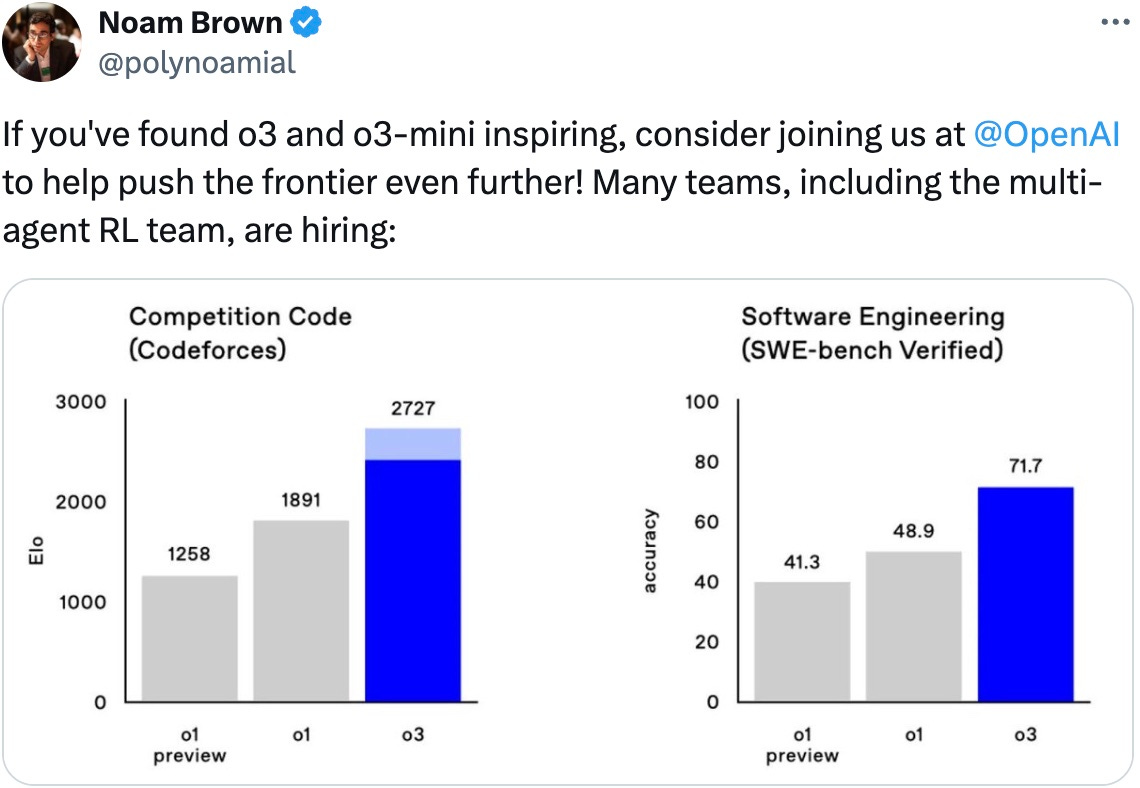
The O-series from OpenAI, including earlier releases like O1 and O2, uses chains of thought in the textual realm. In this framework, a model generates extensive intermediate reasoning steps. A verifier then evaluates each step, reinforcing correct calculations and minimizing errors. The same principle applies to multi-modal contexts: a generator produces potential outputs, while a verifier scrutinizes them against known benchmarks or objective standards. According to Noam Brown’s hints on upcoming O-series capabilities, this verifying mechanism optimizes inference by filtering out invalid solutions.
Potential Extension to Video Generation
The next logical leap involves applying the O-series logic to real-world frames. One would feed, for instance, 100 frames of an actual video segment and instruct the model to propose the next 24 plausible frames. Because ground-truth data for those 24 frames exists, the model can be trained via reinforcement learning. Incorrect sequences train the verifier to be more discerning, and correct sequences refine the generative backbone. Over time, this loop yields higher-fidelity video outputs that align with physical constraints.
Comparisons and Evidence
VO2 vs. Sora
In user demonstrations, VO2 excels at close adherence to prompts—such as exact numbers of figures in a scene—though with a recognizable aesthetic. Meanwhile, Sora might produce higher-resolution imagery but at the cost of unpredictability. Generating police body-cam footage, for instance, highlights how Sora yields varied (often misaligned) outcomes, whereas VO2 remains more precise.
Benchmark Perspectives
Despite VO2’s promise, the broader community notes these solutions have not yet attained the “O-series level” in video. The GPT-4 era has marked an inflection point, revealing “sparks” of advanced capabilities across domains. Yet the consensus is that upcoming iterations, possibly akin to an “O3 announcement”, will reach a markedly higher standard.
Quotes and Admissions
Direct insights from Lukasz Kaiser and Noam Brown reinforce the importance of a generator-verifier gap. In Noam Brown’s example, verifying certain outputs (e.g., math proofs) can be simpler than generating them from scratch. This approach is extendable to video by verifying whether a generated frame set matches known physics or ground-truth footage.
Significance for AI Investors and Researchers
Potential for Synthetic Training Data
From a technical standpoint, one of the most intriguing applications of advanced text-to-video models lies in generating synthetic training data for robotics. Industrial robots traditionally depend on structured environments and carefully curated datasets. However, text-to-video platforms—particularly those with strong controllability like VO2—open a path to producing large volumes of realistic visual scenarios. These synthetic environments can expose robots to conditions beyond their current physical workspace, helping them learn behaviors without immediate access to real-world facilities.
Extending to Long-Horizon Scenarios
Robotic tasks often require extended sequences of actions and interactions with dynamic objects. Generating longer, coherent video segments that accurately reflect physical laws and constraints is particularly challenging. Sora, for instance, has demonstrated issues in maintaining detailed prompt adherence across extended footage, while VO2 does somewhat better at specifying consistent features. Even so, engineering a chain of frames with precise continuity and context remains an unsolved problem for both models. Researchers can experiment with segment-by-segment generation or multi-stage prompt engineering to approximate longer-horizon tasks for robotic simulation.
Real-Time Learning Opportunities
In industrial settings, a core ambition is enabling robots to respond nimbly to unforeseen scenarios. Advanced video models could support real-time adjustment and “on-the-fly” learning if, for instance, a robot’s onboard system or edge server can generate custom micro-scenarios. Such scenarios might depict modifications in a production line or the addition of new machinery before it is physically present. By cycling through these synthetic videos, a robot’s control and vision systems could refine decision-making and reduce the time needed for real-world adaptation.
Challenges in Fidelity and Control
Despite these advantages, maintaining accurate physics and realistic object interactions continues to be a major hurdle. While the O-series approach suggests new paths for verifying frame sequences, each model iteration still struggles with anomalies—missing limbs, incorrect object proportions, or abrupt scene transitions. The capacity of verifiers to systematically evaluate frame continuity holds promise, yet it is not trivial to replicate real-world complexity in purely synthetic datasets. Thus, bridging text-to-video generation with domain-specific physics engines will likely become a central research focus.