



Manus AI: Dissecting the Hype and Uncovering AI’s Physical Limitations
The State of Industrial AI - E89

In recent days, the AI landscape has been shaken by a surge of innovations. Amid a dozen underrated developments, one tool has captured unprecedented attention—Manus AI. Suddenly, millions are on its waitlist, and conversations across industry circles are buzzing. At Essentia Ventures, we’ve taken a deep dive into what makes Manus AI so hyped, and more importantly, how it compares against other advanced systems in practical tasks.
I. The Blueprint of a Perfect AI Hype Campaign
Imagine a campaign that positions its product as “a glimpse into potential AGI.” Instead of merely generating ideas, this product delivers tangible results. Here’s a breakdown of the winning formula we’ve observed:
Bold Claims and Exclusive Access:
Manus AI is presented as a breakthrough in human–machine collaboration—a tool that not only innovates but pushes toward AGI. By placing it behind an exclusive waitlist and rewarding early access, companies create a scarcity that drives buzz. See how scarcity can drive conversation with these hype examples, another example, and one more.
Selective Benchmarking:
The narrative is reinforced by citing impressive benchmarks—like the Gaia Benchmark—while deliberately showcasing only the score where Manus AI outperforms competitors. Such strategic omission preserves an air of mystery while fueling anticipation.Keeping Technical Details Under Wraps:
For instance, subtle references to the system’s reliance on other models are made without overshadowing its innovative promise. A recent Xiao Hong interview even hints at the delicate balance between promise and performance.
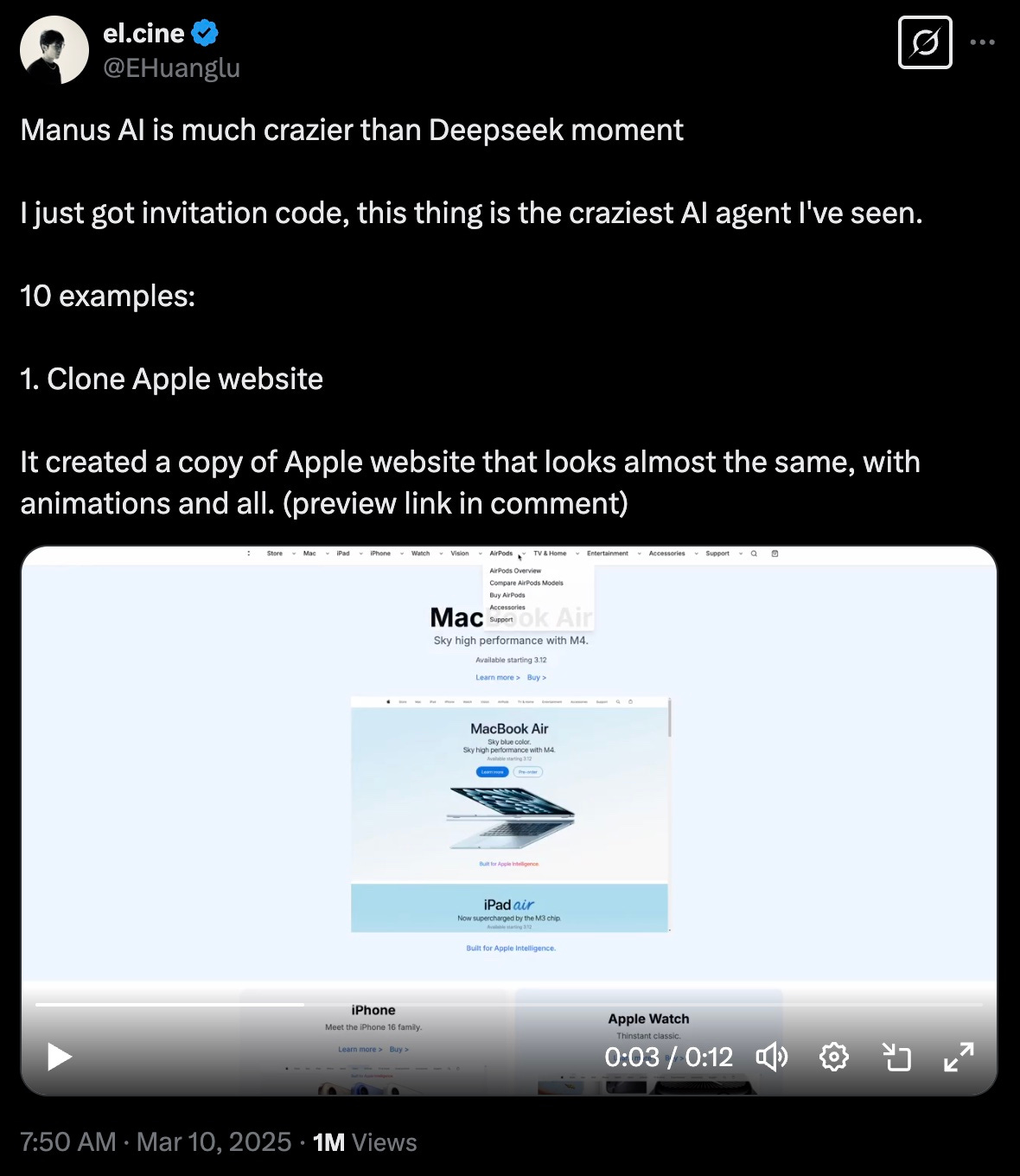
This well-crafted hype strategy is key to why some industry voices have even claimed that “China reached AGI with Manus before we even saw GPT-5.”
II. Unifying Diverse AI Capabilities
At its core, Manus AI is a sophisticated integration of functionalities reminiscent of OpenAI’s Operator and Deep Research systems. It’s not merely about generating text or images—it’s about connecting the dots between various tasks. In our tests, Manus AI was tasked with creating dynamic, interactive web content that summarized recent trends in LLMs. The result was a real-time, context-aware output that, while impressive in integration, still left room for improvement in precision.
Here’s a snapshot of how Manus AI compares:
Speed: Gemini’s advanced deep research delivers results in a flash, while Grok 3 took a few minutes to process over 300 sources.
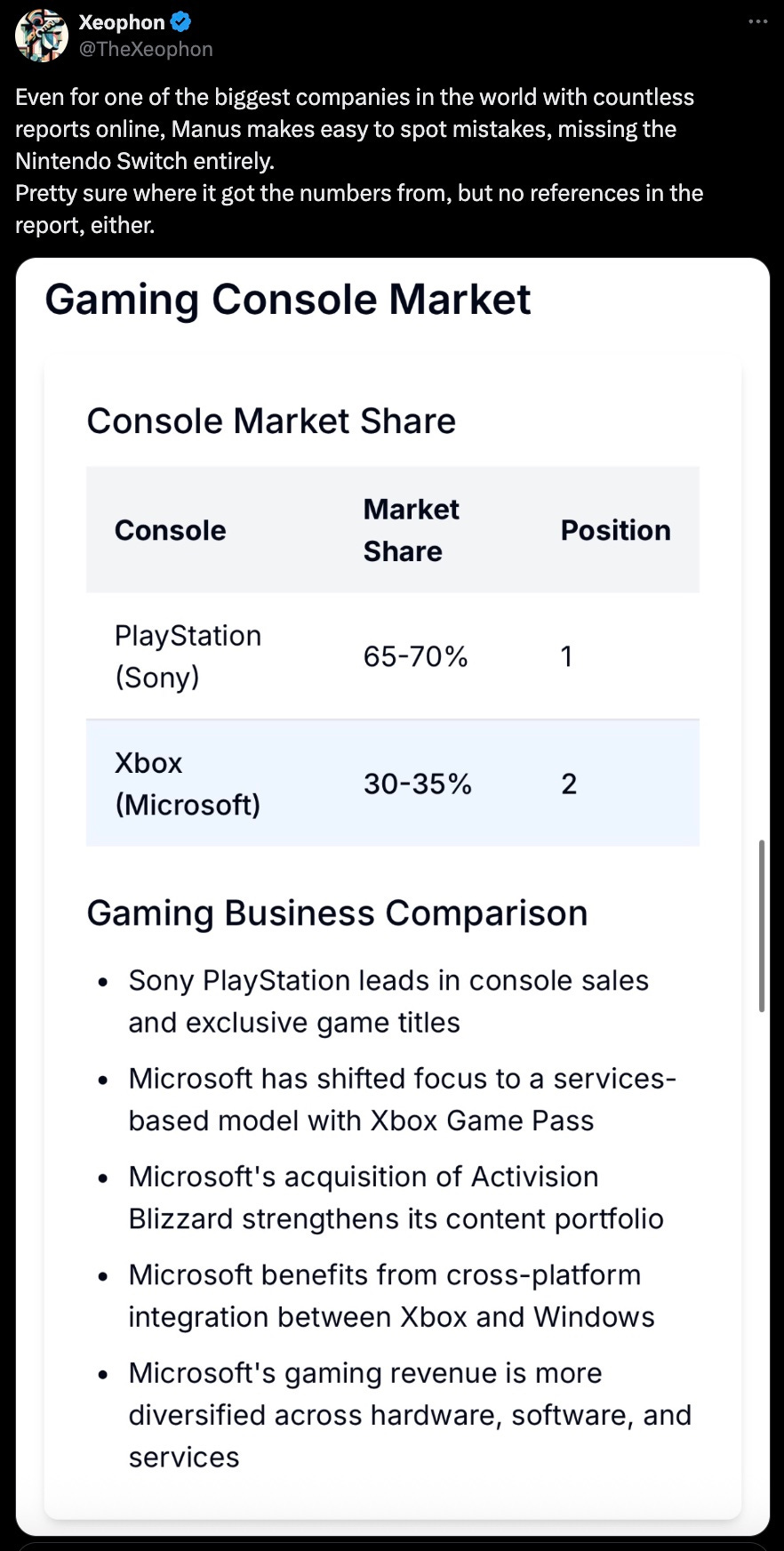
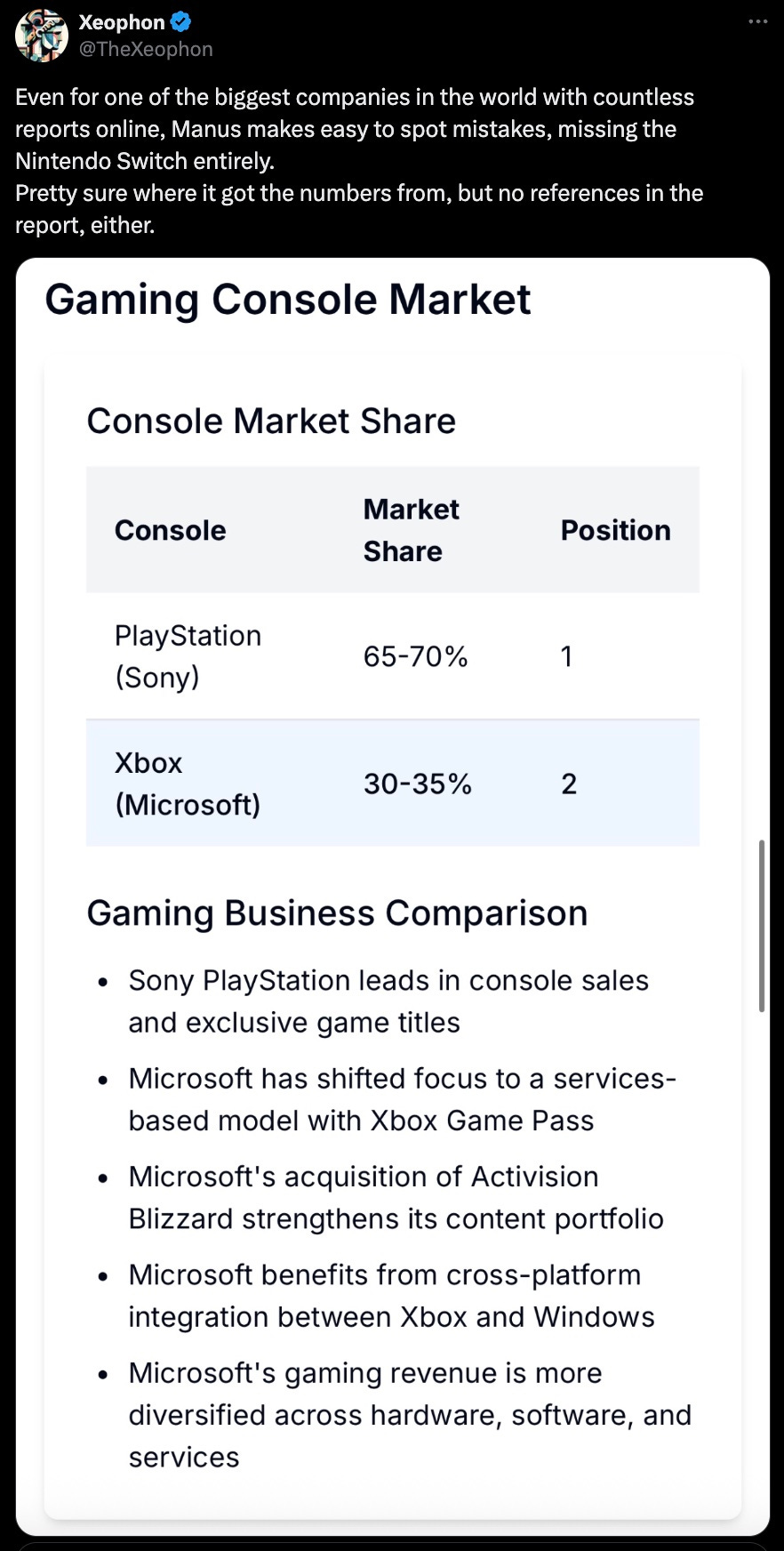
Accuracy: Both Manus AI and OpenAI’s Deep Research operate on similar timeframes (around 15 minutes), but Manus AI occasionally faltered—missing key details like in this example.
Cost Considerations: With an estimated cost near $2 per query—as noted in a recent MIT Report—questions about scalability and efficiency naturally arise. An Information Report dives deeper into these trends.
III. Testing AI’s Physical Understanding: A Series of Experiments
Beyond marketing, it’s crucial to understand where AI truly stands in terms of practical comprehension—especially in physics. We set up a series of experiments designed to test whether advanced AI models can grasp the physical realities of the world around them.
A. Understanding Visual and Physical Dynamics
A central question in today’s AI discourse is: Do these systems really understand what they see? Generating photorealistic videos is one thing; understanding the underlying physics is another entirely. Recent studies have challenged AI models by asking them to predict what happens next in a scene—like a classic visual IQ test.
B. Experiment Highlights
The Rotating Teapot:
In one experiment, a simple rotating teapot was used as a test case. One model, Pika 1.0, surprisingly predicted that the teapot would morph into a pedestal rather than rotate—a result that was, frankly, disastrous. In contrast, Lumiere accurately predicted rotation, though it misplaced key details (like the handles). Meanwhile, OpenAI’s Sora and Runway’s Gen3 provided more reasonable, though still imperfect, outputs.The Painting Challenge:
When tasked with predicting the outcome of a painting scenario involving subtle rotation, Sora’s performance degraded sharply, while VideoPoet managed a moderately accurate response. The inconsistencies across models underscore the difficulty these systems have with even straightforward physical dynamics.Heavy vs. Light Objects:
In another test, the impact of a heavy kettlebell versus a light scrap of paper on a pillow was evaluated. VideoPoet described a dramatic interaction that did not match reality, and other models produced equally off-target predictions. Each system struggled to reconcile the expected physical behavior.Fire in Water:
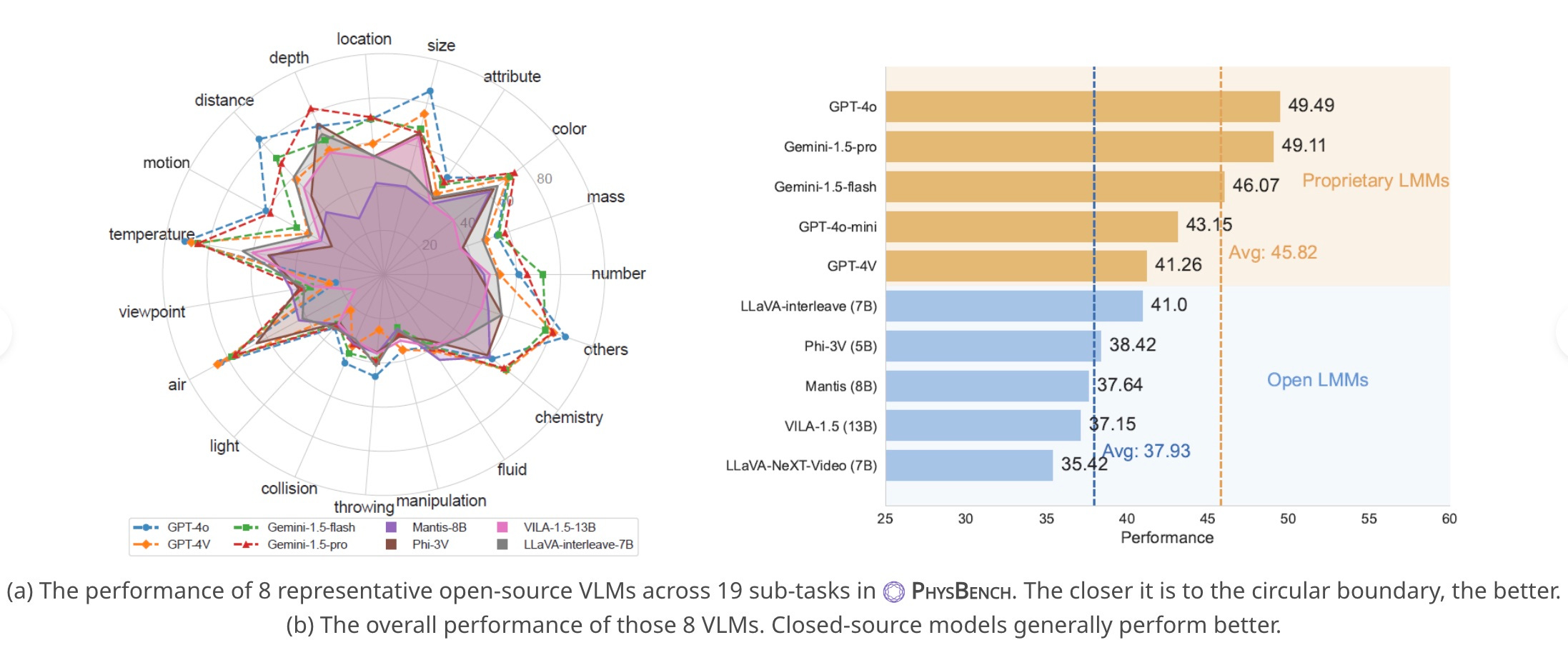
Perhaps the most dramatic test involved placing a burning match in water. Predictions ranged from the match floating, to an explosion, to even an absurd cycle of ignition and re-ignition. These experiments spanned topics from solid and fluid dynamics to optics, thermodynamics, and magnetism. The consensus? Most models score below 30% accuracy on these physical IQ tests. Detailed findings from these studies are available in the Physics IQ Papers and PhysBench.
C. Lessons Learned
What do these experiments tell us? While state-of-the-art AI can generate stunningly photorealistic images and videos, they often lack a true understanding of the physical principles that govern our world. A further study even tested GPT-like AI assistants with questions about temperature, air pressure, and other physical phenomena—and the results were uniformly disappointing. The challenges lie in:
Training Focus: Most AI systems are not primarily trained on physical reasoning.
Plateauing Performance: Increasing training does not necessarily lead to better scores on these tests.
Thank you for reading, and let’s continue pushing the boundaries of what AI can—and cannot—do.